Topic Modelling With Quantized LLaMA 3 & BERTopic

Today we’re diving into topic modeling using a powerful algorithm called BERTopic, and Llama-3, the next generation of Llama, is now available for broad use. It features pre-trained and instruction-fine-tuned language models with 8B and 70B parameters, supporting various use cases. We will be using topic modeling for topic extraction using BERTopic and the quantized gguf version of Llama-3–8b-instruct from the dataset, and visualizing it for further understanding.
What is Topic Modeling?
Businesses need help with vast amounts of unstructured text daily, ranging from customer emails to online reviews. This abundance of textual data necessitates efficient organization and understanding, leading us to rely on topic modeling.
Topic modeling is a statistical technique using unsupervised machine learning to uncover and showcase thematic structures within textual data. It’s crucial in various domains like information retrieval, text mining, modern search systems, and data visualization. These applications enable researchers to explore vast textual datasets efficiently.
The complexity of unstructured text data has historically posed challenges, including a lack of labeled data, limited context understanding, and difficulties in topic interpretation. Additionally, traditional topic modeling methods needed more scalability and pre-trained models, further hindering efficient analysis. However, recent advancements in natural language processing (NLP), particularly with the development of large language models (LLMs) like ChatGPT and GPT-4, have revolutionized topic modeling efficiency, especially for smaller datasets.
While LLMs offer improved capabilities, directly passing all documents for analysis remains computationally impractical. Here, BERTopic emerges as a potent solution, leveraging Transformer models’ language comprehension and C-TF-IDF to create dense clusters of coherent topics. Instead of analyzing each document individually, BERTopic’s clusters provide a foundation for LLMs to distill and fine-tune topic representations accurately.
By leveraging BERTopic’s clustering abilities, we can improve topic modeling with LLMs, optimizing the analysis of large textual datasets without excessive computational requirements.
Why LLaMA-3 instead of ChatGPT or Gemini?
The Llama 3 language model is trained on a large, high-quality pretraining dataset of over 15T tokens from publicly available sources.
The dataset is seven times larger than Llama 2 and includes four times more code. Over 5% of the dataset is non-English, covering over 30 languages. To ensure high-quality data, a series of data-filtering pipelines are developed, including heuristic filters, NSFW filters, semantic deduplication approaches, and text classifiers. Experiments are conducted to select the best data mix for Llama 3.
Llama 3 demonstrates superior capabilities across various AI benchmarks. The 8B model excels in human-like evaluations, while the 70B model shows outstanding performance in complex reasoning and mathematical tasks, surpassing other leading models such as Gemini Pro 1.5 and Claude 3 Sonnet and 8B outperforming Gemma 7B and Mistral 7B instruct.
The LMSYS Chatbot Arena uses over 800,000 human comparisons to rank large language models (LLMs) on an Elo scale. Currently, the Llama 3 70B-Instruct model holds the 6th position on this leaderboard, demonstrating its robust performance in real-world conversational settings. According to Meta’s Llama 3 release blog, the 8B model is the best in its category
Despite its high performance, Llama 3 is available at a fraction of the cost of comparable models like GPT-4. This price advantage, coupled with its open-source model, democratizes access to cutting-edge AI technologies, making it a financially attractive option for developers and businesses.
Let’s Implement the Topic Model on ML Research Papers!
We will start by installing many packages that we are going to use throughout this Tutorial:
%%capture
# BERTopic + llama-cpp-python
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python
!pip install bertopic datasets
# DataMapPlot
!git clone https://github.com/TutteInstitute/datamapplot.git
!pip install datamapplot/.
# GPU-accelerated HDBSCAN + UMAP
!pip install cudf-cu12 dask-cudf-cu12 --extra-index-url=https://pypi.nvidia.com
!pip install cuml-cu12 --extra-index-url=https://pypi.nvidia.com
!pip install cugraph-cu12 --extra-index-url=https://pypi.nvidia.com
!pip install cupy-cuda12x -f https://pip.cupy.dev/aarch64Now we will import all necessary modules that are going to be used to create a topic model
from datasets import load_dataset # For loading the dataset from Hugging Face
from huggingface_hub import hf_hub_download # For loading the model instance from Hugging Face
import os # For creating system directories
from llama_cpp import Llama # LLM Wrapper
from bertopic.representation import KeyBERTInspired, LlamaCPP # Representation Comparison
from sentence_transformers import SentenceTransformer # Embedding Model Wrapper
from cuml.manifold import UMAP # For UMAP dimensionality reduction
from cuml.cluster import HDBSCAN # For clustering with HDBSCAN
from bertopic import BERTopic # For topic modeling with BERTopic
import PIL # For image processing
import numpy as np # For numerical computations
import requests # For making HTTP requests
import datamapplot # For data visualization
import re # For regular expressionsUse topic modeling on several ArXiv dataset’s abstracts and for the model, we make use of the llama-3–8b-instruct-GGUF format together with llama-cpp-python from Huggingface.
model_name_or_path = "NousResearch/Meta-Llama-3-8B-Instruct-GGUF"
model_basename = "Meta-Llama-3-8B-Instruct-Q4_K_M.gguf"
os.makedirs('model', exist_ok=True)
path = "model"
# Downloading the model from repo
model_path = hf_hub_download(repo_id=model_name_or_path, filename=model_basename, cache_dir=path)
# ArXiv ML Documents
docs = load_dataset("CShorten/CORD19-init-160k")["train"]["abstract"] # CShorten/1000-CORD19-Papers-Text
# Use llama.cpp to load in a Quantized LLM
llm = Llama(model_path=model_path, n_gpu_layers=-1, n_ctx=4096, stop=["Q:", "\n"],verbose=False)Once the LLM is loaded, a KeyBERTInspired representation is added to compare with the Llm representation, and the document is converted to a numeric representation using a sentence transformer, a model optimized for semantic similarity. These models are very useful for clustering tasks and can efficiently create embedding of documents and statements. Precomputing the embedding of each document speeds up the search procedure and allows you to quickly iterate over the hyperparameters of BERTopic as needed. In this case, we are using the BAAI/bge-small-en-v1.5 model.
After you get the numeric document representation, you need to reduce their dimensions. Cluster models often struggle with high-dimensional data because of the curse of dimensionality. Methods such as PCA are effective for reducing dimensions, but the default choice of BERTopic is UMAP. UMAP is a technique that preserves both the local and global structure of a dataset while reducing its dimensions. It is very important to retain this structure because it contains information that is essential for creating a cluster of semantically similar documents.
Next, we define the UMAP and HDBSCAN models.
prompt = """ Q:
I have a topic that contains the following documents:
[DOCUMENTS]
The topic is described by the following keywords: '[KEYWORDS]'.
Based on the above information, can you give a short label of the topic of at most 5 words?
A:
"""
representation_model = {
"KeyBERT": KeyBERTInspired(),
"LLM": LlamaCPP(llm, prompt=prompt),
}
# Pre-calculate embeddings
embedding_model = SentenceTransformer("BAAI/bge-small-en-v1.5")
embeddings = embedding_model.encode(docs, show_progress_bar=True)
# Pre-reduce embeddings for visualization purposes
reduced_embeddings = UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine', random_state=42).fit_transform(embeddings)
# Define sub-models
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
hdbscan_model = HDBSCAN(min_cluster_size=400, metric='euclidean', cluster_selection_method='eom', prediction_data=True)Now that we have our models prepared, we can start training our topic model by using BERTopic with sub-model for Extract embeddings through SentenceTransformer, Reducing dimensionality through UMAP, cluster-reduced embeddings through HDBSCAN, and fine-tuning topic representations through Llama-3–8b-instruct and KeyBERTInspired. To get more details, check out this link.
topic_model = BERTopic(
# Sub-models
embedding_model=embedding_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
representation_model=representation_model,
# Hyperparameters
top_n_words=10,
verbose=True
)
# Train model
topics, probs = topic_model.fit_transform(docs, embeddings)
# Show topics
topic_model.get_topic_info()After running .fit_transform, let’s see what kind of topics we get in visualization.
# Prepare logo
bertopic_logo_response = requests.get(
"https://raw.githubusercontent.com/MaartenGr/BERTopic/master/images/logo.png",
stream=True,
headers={'User-Agent': 'My User Agent 1.0'}
)
bertopic_logo = np.asarray(PIL.Image.open(bertopic_logo_response.raw))
# Create a label for each document
llm_labels = [re.sub(r'\W+', ' ', label[0][0].split("\n")[0].replace('"', '')) for label in topic_model.get_topics(full=True)["LLM"].values()]
llm_labels = [label if label else "Unlabelled" for label in llm_labels]
all_labels = [llm_labels[topic+topic_model._outliers] if topic != -1 else "Unlabelled" for topic in topics]
# Run the visualization
datamapplot.create_plot(
reduced_embeddings,
all_labels,
label_font_size=11,
title="ArXiv - BERTopic",
sub_title="Topics labeled with `llama-3-8b-instruct`",
label_wrap_width=20,
use_medoids=True,
logo=bertopic_logo,
logo_width=0.16
);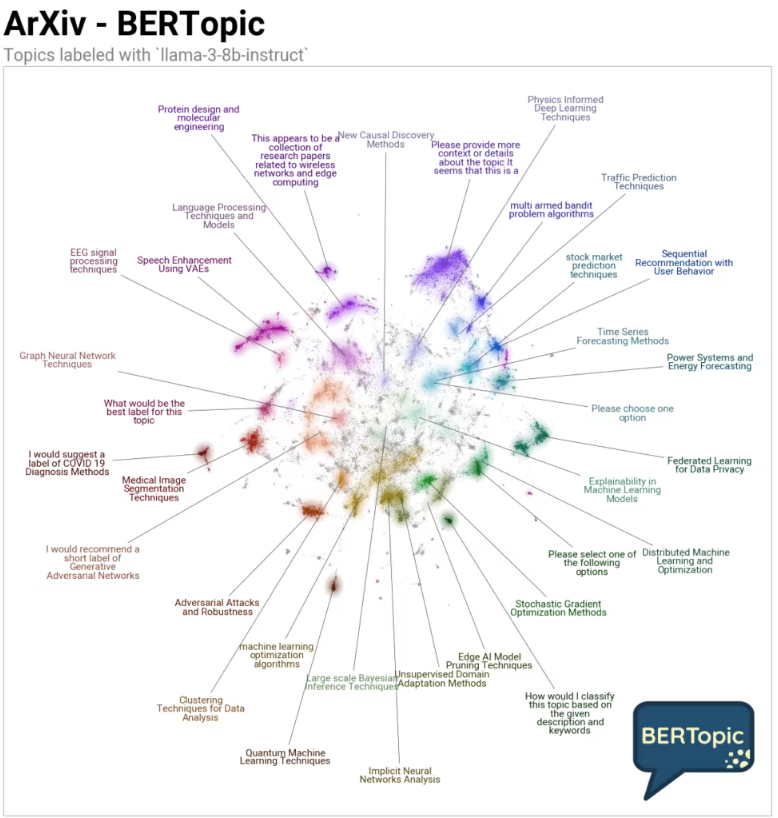
In this visualization, some unwanted labels have come up, to avoid you have to test the sub-model with different hyperparameters and choose appropriate ones over your dataset
Furthermore, I would suggest you explore the original documentation and another article to understand it better.
Conclusion
The article explores topic modelling using advanced algorithms like BERTopic and Llama-3, highlighting their significance in managing vast amounts of unstructured text data. It explains the challenges faced by traditional topic modeling methods and introduces BERTopic as a robust algorithm leveraging Transformer models for clustering coherent topics. Llama-3, a next-gen large language model, is also introduced for its superior performance and capabilities.
The implementation process involves installing necessary packages, loading datasets, utilizing pre-trained models, generating embeddings, reducing dimensionality, clustering documents, and fine-tuning topic representations. The article concludes with a visualization using DataMapPlot to showcase clusters of similar documents labelled with topics derived from Llama-3–8b-instruct. Overall, these advancements empower businesses and researchers to extract meaningful insights from textual data efficiently, aiding in decision-making and knowledge discovery.



Comments
Post a Comment